Disentanglement of Hetergeneous Components:
A Slightly Obsolete Attempt
I studied the problem of disentanglement with a special yet very natural assumption and give a new formulation of objective, by a careful inspection and re-writing of ELBO. It turns out that the new objective surprisingly coincides with Schmidhuber's work
The subtitle is dubbed 'an obsolete attempt' simply because of the ICML 2019 paper
People who are familiar with the topic can start with the subsection Decomposing ELBO.
Structure
-
Introduction
Introduce the problem and the perspective of our new assumption.
-
Inspect ELBO
Start from the beginning of variational autoencoders, and see if the implicit notion of heterogeneous components can be induced directly from the original evidence lower bound objective (ELBO).
-
New objective for disentanglement under this new assumption
At the core of it is the new proposed Latent Transport Discrepancy (LTD).
We are interested in learning disentangled representations that uncovers multiple underlying generative factors from real-world observations. We argue that these factors should have heterogeneous natures -- following different sizes and prior distributions. Previous approaches, such as setting a unit Gaussion as prior, lacks flexibility regarding latent representations' capacity to capture the true generative factors. The problem here is how to come up with a some-what agnostic approach for disentanglement learning, agnostic to those different sizes&priors. In this paper, we leverage the disentangled representation learning to the component-level where heterogeneous components could use different sizes and prior distributions and independently controls the true generative factors of variations.
Introduction
The world is inherently well structured, or at least we human beings would be very happy to assume so. It is quite common for us to assume that real-world observations are controlled by a set of components. For example, a in-room object could be parameterized by 'object type', 'postion', 'color' and 'size' and we know that these properties could be easily controlled without effecting the others, if we are the programmers of this world -- this is exactly when we say we learned the disentangled representations of this object. It becomes even clearer to us that in computer graphics when we are designing a virtual object in video games, we understand the disentanglement and actually have the power to manipulate these parameters. This problem is formally refered as disentangled representation learning which, according to
Our hypothesis is that these components -- some times we call factors of variation, or representations -- could be of heterogeneous nature. That is, some components may be simple, taking only a binary value, while others could be very complex, being multivariate variables. Previous work on disentangle representation learning are all working on the dimension level, representing components using the same capacity, disregarding that different factors of variation could be heterogeneous and cannot be all represented by just one dimension.
We propose a general framework to learn disentangled heterogeneous components that could represent and manipulate the factors of variation independently. Previous appoaches fail or simply ignore to consider the independence between latent representation such as the vanilla VAE
Background
Let to be the set of real-world observations and the true latent representations, which is not available. Let to be the latent code consists of components where each could be of different size and prior distributions.
Variational Auto-encoding Bayes
Given a generative model parameterized by , we are interested in finding an appropriate approximate posterior inference model i.e., the latent variable given an observation .
Let us now introduce as a recognition model to approximate the intractable true posterior with the prior . Normally, is deliberately chosen to be simple, such as an isotropic unit Gaussian .
We aim at maximizing the likelihood as well as minimizing the divergence between and which we shall use Kullback-Leiler divergence to measure.
This likelihood is intractable to directly optimized, since it requires integration over entrie space of . The classic approach
which is commonly refered as the Evidence Lower Bound Objective (ELBO). This ELBO has a very intuitive interpretation that the first term is the expected negative reconstruction error while the second term acts as regularization, to fit the approximate posterior with the prior distribution.
This variational lower bound could be efficiently estimated by the SGVB estimator in the auto-encoding framework using the reparameterization trick
Representation Disentanglement
VAEs trained with even vanilla ELBO shows good disentanglement, for example, in MNIST digit images
We set to be a large constant (typically ), the modified objective puts extra penalty encouraging the model to learn independent disentangled latent representations.
On the other hand, several supervised methods have managed to learn independent latent representations that are sensitive to single-dimension generative factors, for example, Inverse-Graphics Network
Problems
However, despite the successful disentanglement and reconstruction on various datasets, we find thatthe vanilla ELBO objective, which is the base stone for many works, still suffers some severe problems in the learning of disentangled representations.
The Information Preference Problem (or known as the posterior collapse)
One of the most common problem is the extremely poor amortized approximation of posterior probabilty, which is first formally studied in
Let us take a closer look back at the original ELBO, it turns out that with a sufficienty expressive conditional model, the latent representation for different tends to become completely disjoint and do not overlap one another. Meanwhile the reconstruction term becomes infinitely large, indicating extreme overfiting. In this scenario, the qualitive results would show that, the reconstruction of observations is nearly perfect yet interpolation of two observations or traversal along one dimension would make no sense, failing to capture the true generative process.
On the other hand, putting extra penalty on such as -VAE
The information preference problem tends to encode every sample into different disjoint latent representations, centered at . As a result, the vast majority of the latent space would have near-to-zero probabilistic density, except that for a given sample becomes extremely large.
In other words, the variational inference model inevitably over-estimate the variance when trained to convergence with vanilla ELBO, which is studied in
Choice of Prior
While the original VAE work has been shown to achieve good disentangling performance with a trade-off of reconstruction. We see that on simple datasets, such as FreyFaces or MNIST
The choice of the prior probabilty could influence a lot about the learned inference model as suggested that the prior controls the capacity of the latent information bottleneck. We argue that one way to bypass the information preference trade-off problem is to prvide the VAEs with more flexible prior distributions. If we wish to learn latent representations for a given data set, appropriate priors are an essential step towards successful disentanglement and reconstruction.
However, one remark on the current paradigm of learning independent representation in VAEs is that, the usages of learned representations are only studied at the dimension level, as the qualitive experiment is commonly a traversal along one latent axis where the rest being fiexed, and hence independence of latent representations are introduced at the dimension level. Intuitively, in
Viewing all these problems in a more general perspective where multiple components following different size and priors would be a good solution to scale disentangled representation learning in complex datasets.
Method
Unlike
Where is the mutual information of and .
The second term, KL divergence between the aggragated posterior and the prior could be further decomposed by
The final result in full would be
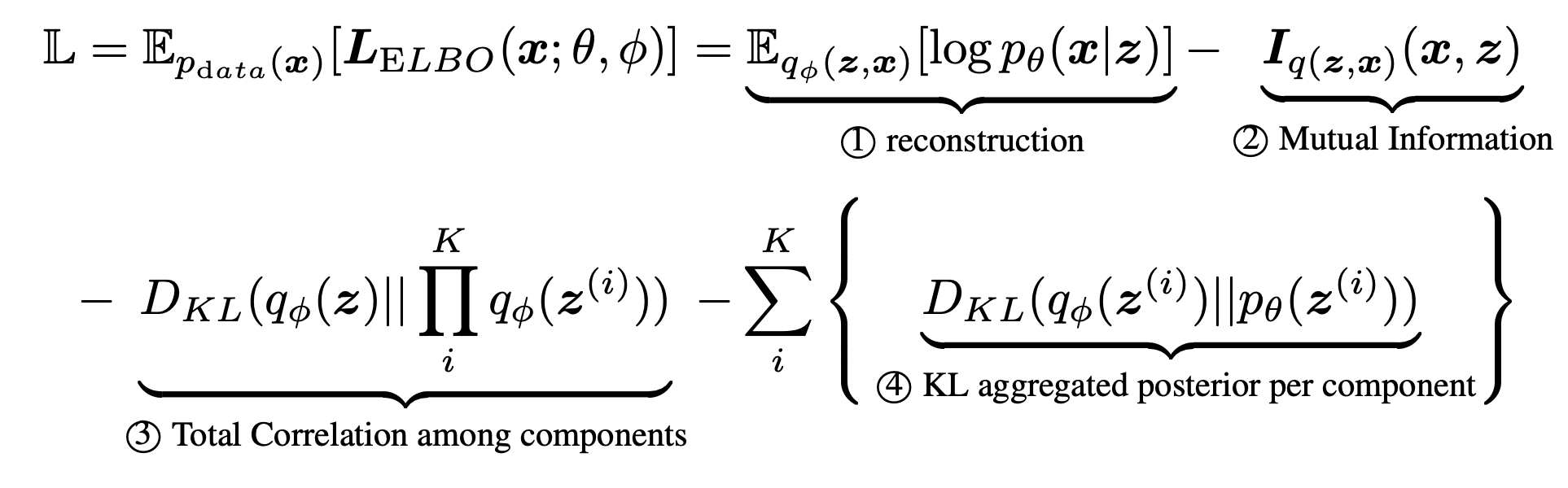
Decomposing ELBO
The above formulation follows a similar decompostion (
Intuition of Formulation
The first term ① could be viewed as the negative reconstruction error recovering the original observation from latent representation. In a similar decomposition
This is in conflict with our optimization objective since we want to maxmize the overall ELBO. Futhermore, despite the fact that ② serve the same intuitive meaning to reconstruct , ② is relatively very weak because it is bounded above and below by and . Some
The third term is refered as the total correlation in information theory, which is in fact a more general form of mutual information with multiple variables.
Intuitively ② captures the multivariate mutual information and could be zero if and only if all components are independent, and has been used to characterize the disentanglement and statistical independence of learned representations (
③ indicates how dependent there variables are, and by penalizing ③ we expected to learn statistically independent components. However, directly optimizing this term is not trackable and always needs construction of and and sample from them.
Measuring the independence among latent variables does not currently have a good solution.
An easy way to bypass this problem is to provide a alterbative optimization objective like
where denotes the covariance.
However, this technique could not generalize to complex cases where different latent components are heterogeneous, having different size of dimesions . We provide in the next section on sculpting latent representations consists of multiple independent heterogeneous components into different priors.
Utilizing Latent Transport Discrepancy
Both the mutual information term and the total correlation could not be directly optimized, suggesting that we need some tricks to make it computationally trackable. In this section, we first show that the total correlation term ③ could be relaxed into a approximation of combinations of component-wise mutual information and then provide a novel framework called Cross-component Transport Discrepancy to provde a simpler and more efficient estimation of pair-wise dependence between each component pair. We reduce ③ to the difference form of information entropies,
The second equation could be gained by applying the inclusion–exclusion principle. We here make a relaxation to disregard the mutual information involving more than two variables and only take into account so that
Note that the total correlation measures the mutual independence among multiple variables, while pair-wise independence does not strictly indicate mutual independence. But this step clearly sets us in a familiar enviroment on modeling the dependence (or independence) between two distributions.
But how to measure mutual information? Note that pair-wise mutual information is still intractable to directly optimize. For simplicity, from now we will assume so that there are only two latent components and , and that they happens to have a prior of isotropic unit Gaussian of and dimensions, respectively. We will move on to other distributions later.
Let us consider the probabilty distribution of and seperately. We denote the conditional transport plan from to and then use an abbreviation .
Our insight here is that if all moments from one distribution could be transported into the other using the same transport plan , i.e. all s are the same for each sample , then these two distributions are in fact equivalent. This could be explained from a mutual information perspective .If these s are to an extent of completely randomness, then it would indicate a near-zero mutual information ,that and are statistically independent. This is actually a adanced form of the optimal transport problem, where the OT problem tries to find the best transport plan given a cost distance, our problem is that when we are given exactly the transport plans for each pair, we want to measure the variance of such plans.
Let's first consider the case where and shares exactly the same distribution and only differs in its mean. Then for each pair of latent representation and , remains a static constant, we shall say in this scenario, and shoud have a high mutual information and are in fact strongly dependent on one another.
In a heterogeneous case where and uses a different size of and dimensions, respectively. We use a linear transport for that and thus
We measure the discrepancy of all s to approximate the mutual information as (see the above figure for illustrated explanation):
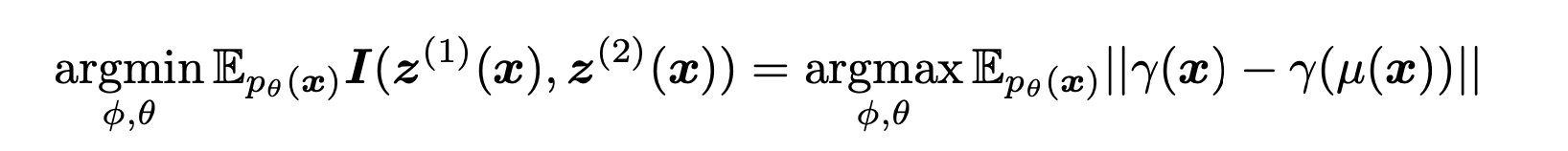
where denotes the mean of and we use a Frobenius norm. If we take to be linear transport , then in order to minimize the mutual information,our objective is to maxmize
The complete form of rewritten ELBO is
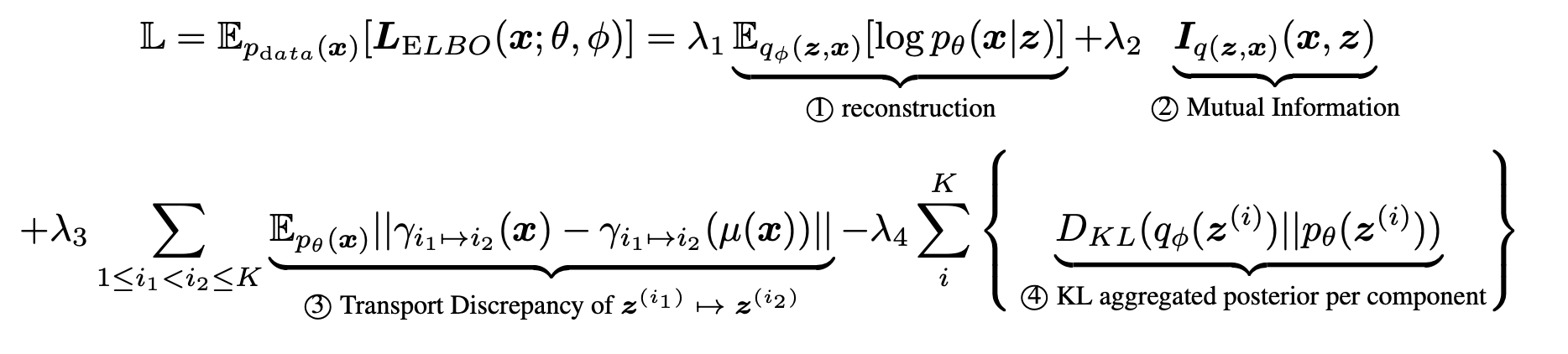
Note that we set to disregard the mutual information between and completely. This objective surprisingly coincides with the probabilty minimization for factorized binary code
Estimator and Algorithm
Note that ④ could be further decomposed into
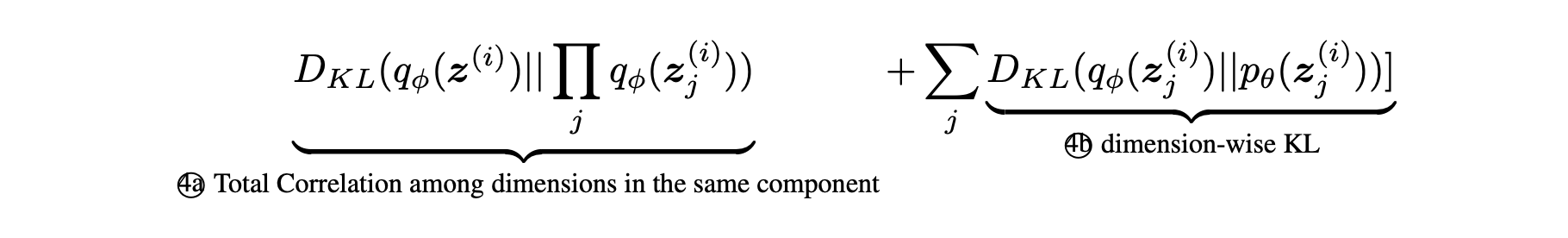
for every component . A similar approach like
For , we employ a similar matching using the maximum mean discrepancy proposed by
Discussion, the disappointing results from Locatello et al, 2018
All the above formulation seems to be sound and good, and I've also experimented and got some good results compared with some baselines on some datasets like cifar and dSprites.
But then comes the ICML 2019 paper
In a massive scale evluation, different baselines of unsupervised disentanglement learning are tested in different datasets with different randomness. The results are frustrating, but somehow it convinced me thoroughly. The unsupervised disentanglement of representation previously lack a rigorous way for evaluation, partially due the fact we do not understand yet the Deep Neural Networks, the architectures we use and the optimization methods like SGD. Too many unknown factors are hidden behind the scene and we dare to play this sophisticated game of disentanglement learning.
But in the other hand, one is also inspired to think alternative ways for the goal of disentanglement. Consider human, which of certainty can do some sort of disentanglement, consider the fact that we can manipulate many factors by imagination in the brain. One way of human learning is the source of various types of weak but diverse learning signals. Yes most of these learning signals are weak, but we have too many types of it. Certainly one or a subset of these signals can really help us and eventually enable us for the disentangled representation we have. One simple option to consider, from my opinion, is the idea of "Active Confirmation". The learner can ask the human or other experts, whether two samples shared some value of generative factors. I am sure some tools of active learning works can be utilized, please contact me should you have some ideas.
I will also see into some literature on active learning on my own.
Conclusion
I give in this post a new formulation of ELBO and a new proposed method for approximation. The resulted formulation is very similar to Schmidhuber's work
Given the frustrating situation of reality, we shall come to a compromise that if we want a VAE inference should perform a good disentanglement on large and complex unsupervised datasets, we might need a little guidance when some auxiliary weak supervision could be provided.
But anyway, for me, I do not believe the problem of disentanglement can be solved in the very near future (for example, 10 years), so do not worry. There is still plenty of time.
Just relax, and play.